1.什么是Maven
Maven简单来说是一个项目管理工具,被认为是Ant的替代品或者继任者。虽然广受诟病,一个不争的事实就是Maven逐渐替代了Ant,使用Maven也成了Java开发人员的一个必要技能。
2.IntelliJ IDEA
在Java的世界里,Eclipse毋容置疑是IDE中的王者,IntelliJ IDEA 也是一个相当优秀的IDE,IntelliJ IDEA提供了大量的智能规则来协助开发者,类似代码补全,用法的转换,格式的提示等等,当你习惯以后,你就会对那个小灯泡爱不释手。
3.Maven + IntelliJ IDEA 的优势
一切都是Module
IntelliJ IDEA借鉴的Maven的概念,不再采取Eclipse里Project的概念,一切都是Module。并且可以混搭使用Maven Module和普通的Java Module,两者可以和谐共存。
4.Maven 安装
到Maven官网下载最新的Maven版本(如果官网打不开,请访问apahce镜像网站下载),我下载的版本为apache-maven-3.0.5。推荐使用最新的Maven 3,因为比以前的Maven 2性能更好,而且完全兼容Maven 2。
下载完成后,解压到一个目录,我的目录为:D:\apache-maven-3.0.5,接着配置Maven环境变量M2_HOME为你解压的目录,如下图新建M2_HOME变量并追加到Path后面: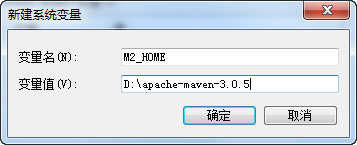
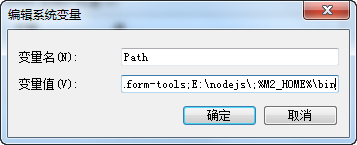
查看Maven是否安装成功:
运行:cmd1
mvn -v
输出

如要想要修改Maven的本地仓库位置,可以在Maven的安装目录下的conf目录下的settings.xml配置文件中设置:

5.Maven 与IntelliJ IDEA完美使用(基于IntelliJ IDEA 14)
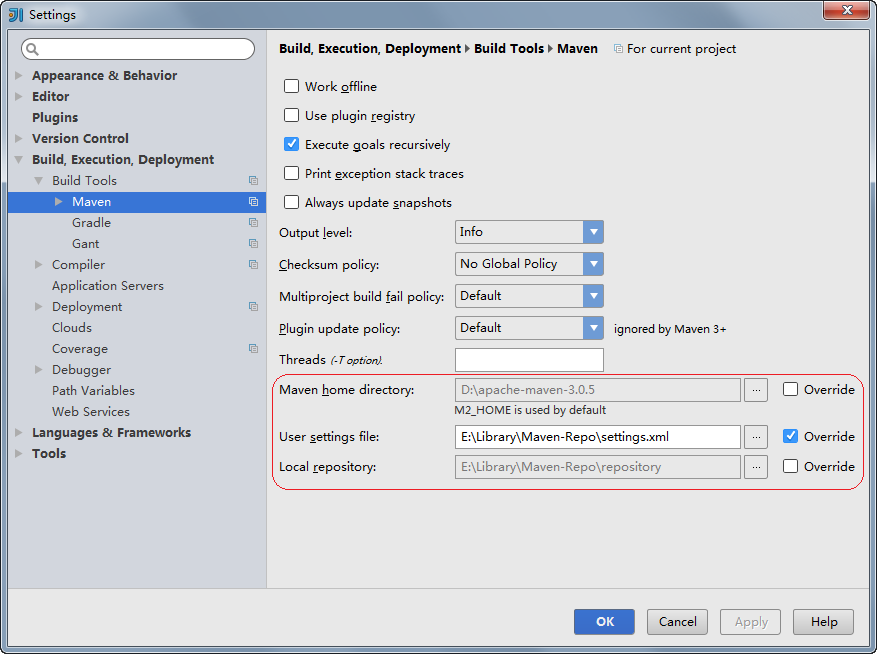
在IntelliJ IDEA的设置中,可以设置Maven的安装目录,settings.xml文件的位置,和本地仓库的位置等信息。
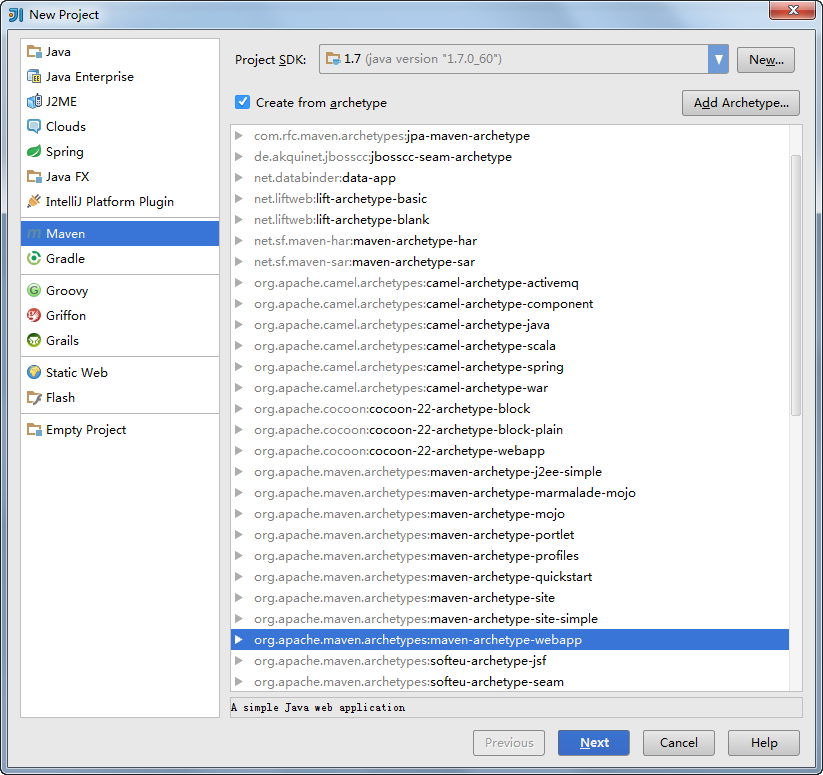
新建Maven项目,create from archetype,选择maven-archetype-webapp
Next,填写GroupId,ArtifactId和Version
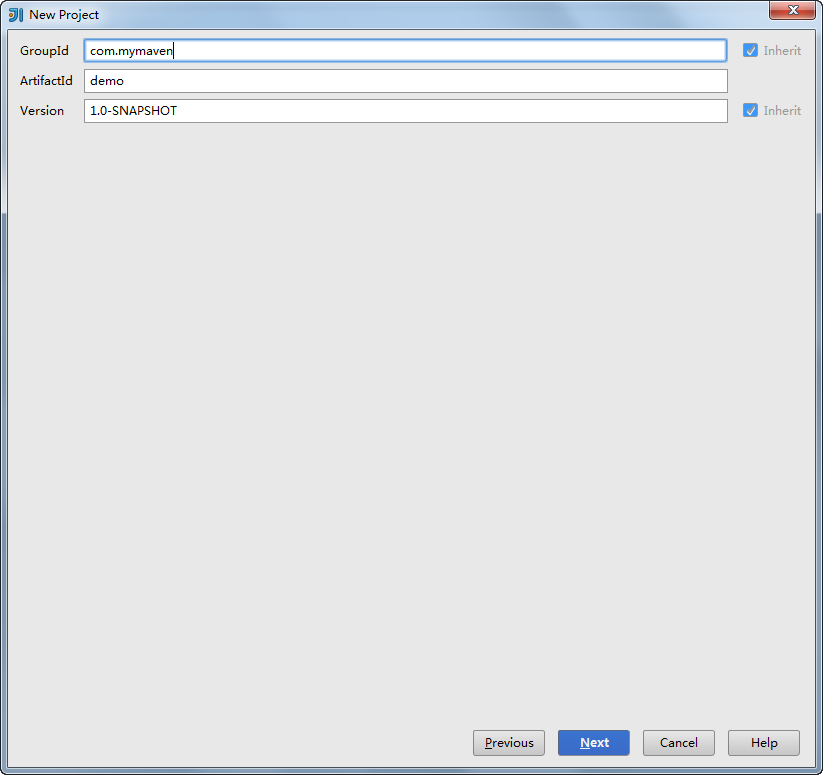
Next,这里在Properties中添加一个参数archetypeCatalog=internal,不加这个参数,在maven生成骨架的时候将会非常慢,有时候会直接卡住。
来自网上的解释:
archetypeCatalog表示插件使用的archetype元数据,不加这个参数时默认为remote,local,即中央仓库archetype元数据,由于中央仓库的archetype太多了,所以导致很慢,指定internal来表示仅使用内部元数据。
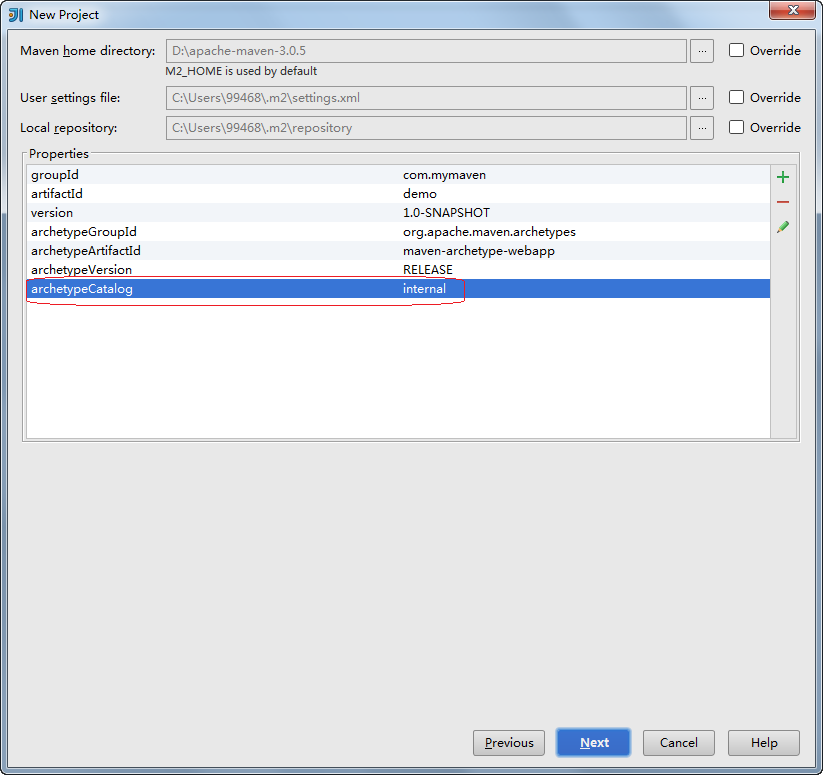
Next,填写项目名称和module名称。
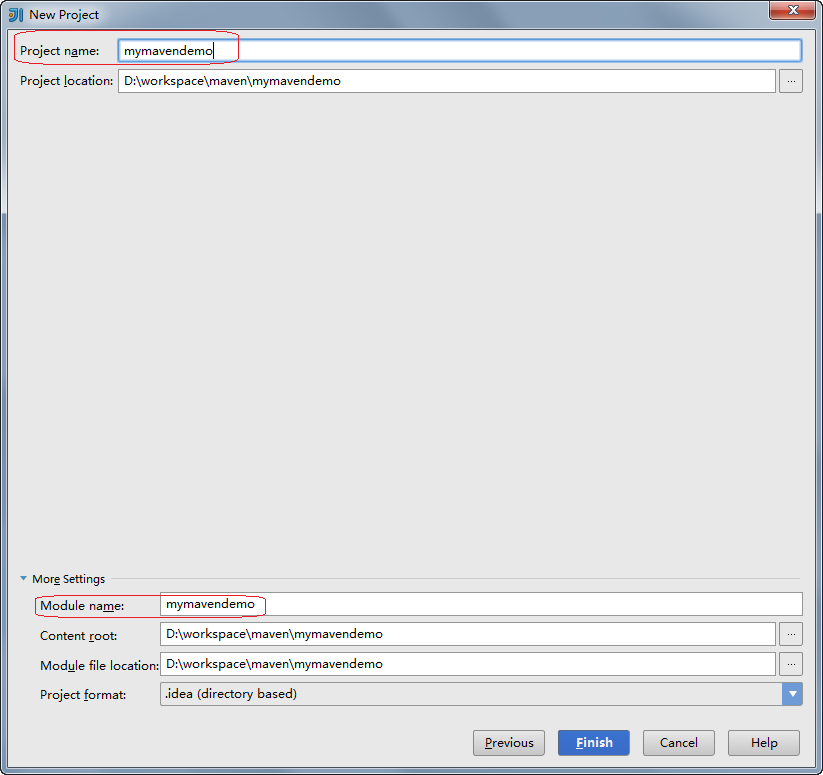
点击Finish。
项目的目录结构如下:
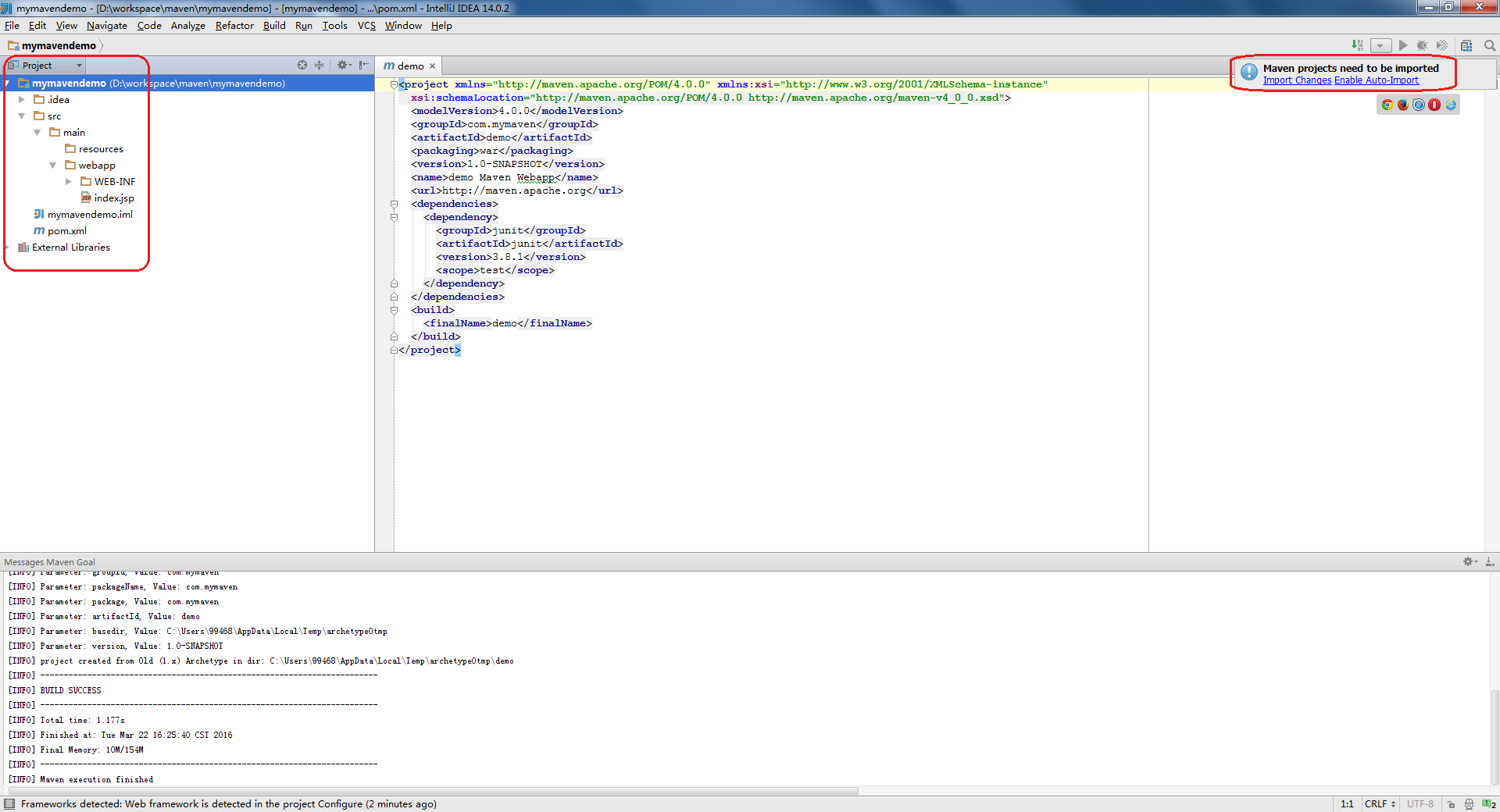
这里IntelliJ弹出了一个对话框”Maven projects need to be imported”,并且项目目录结构中,如果出现该对话框请点击”Enable Auto-Import”,可以在每次修改pom.xml后,自动的下载并导入jar包.
If you see the “Maven projects need to be imported” popup in IntelliJ, then do click “Enable Auto-Import”.
点击后,项目会重新构建,构建后的目录结构如下: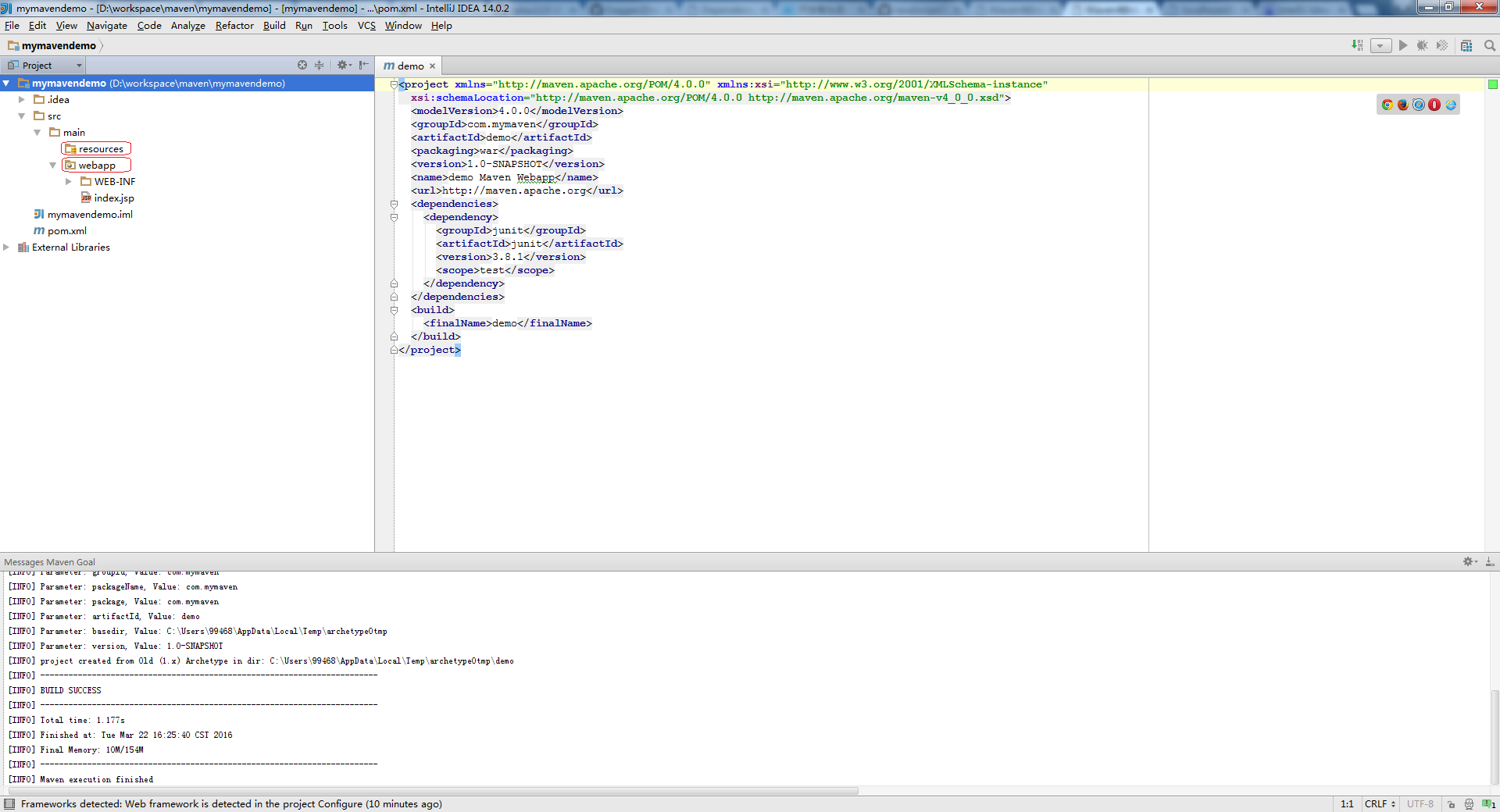
请注意 resources和webapp 文件夹的变化,这个时候项目才是一个web项目。
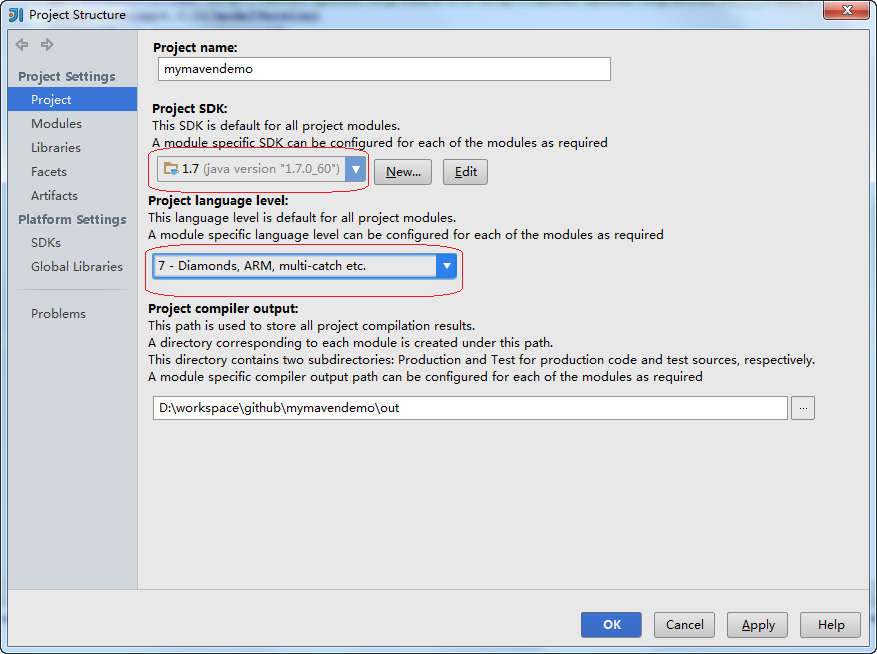
设置
配置项目的JDK和language level
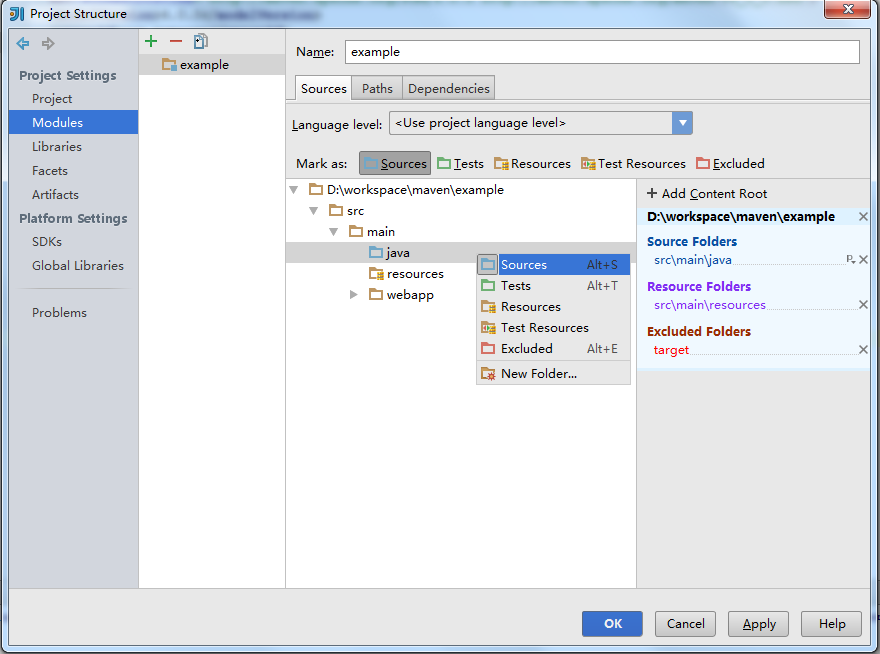
在main文件夹下新建一个java文件夹,把它设为源代码文件夹。
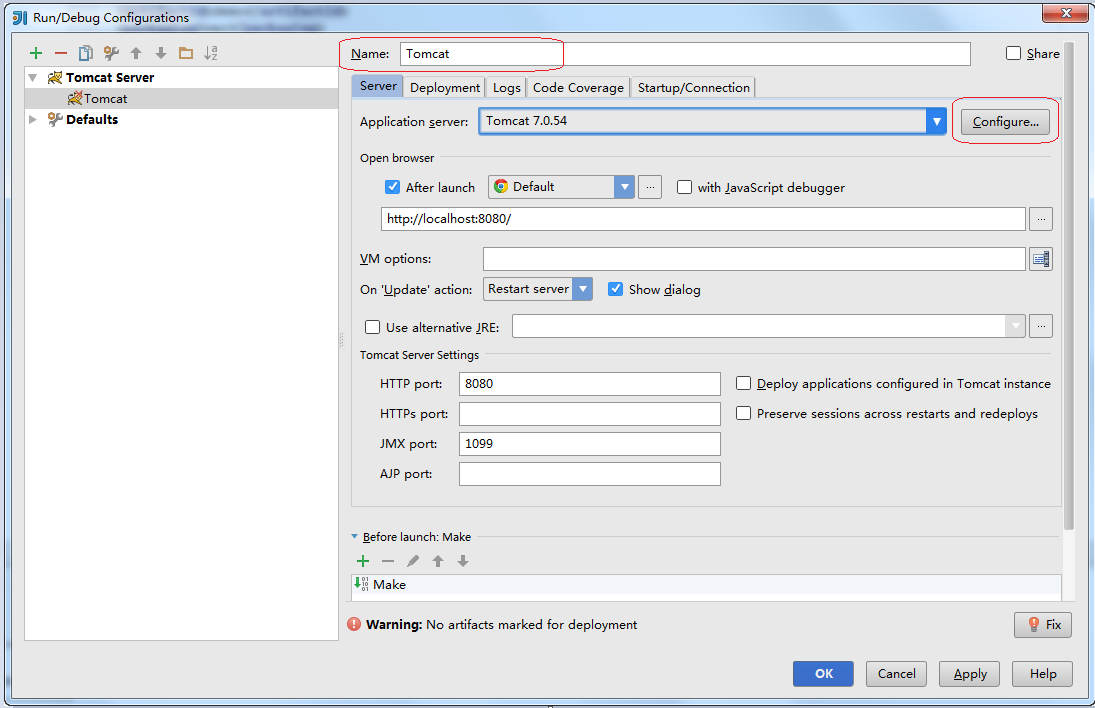
设置Tomcat
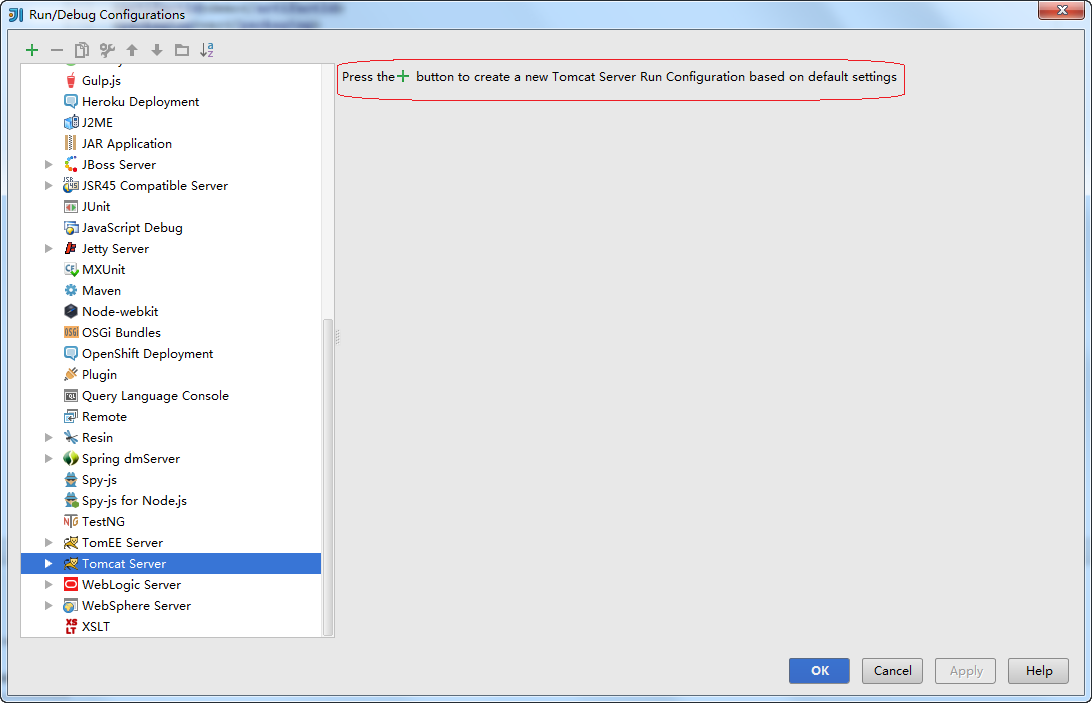
点击+号按钮,选择Local
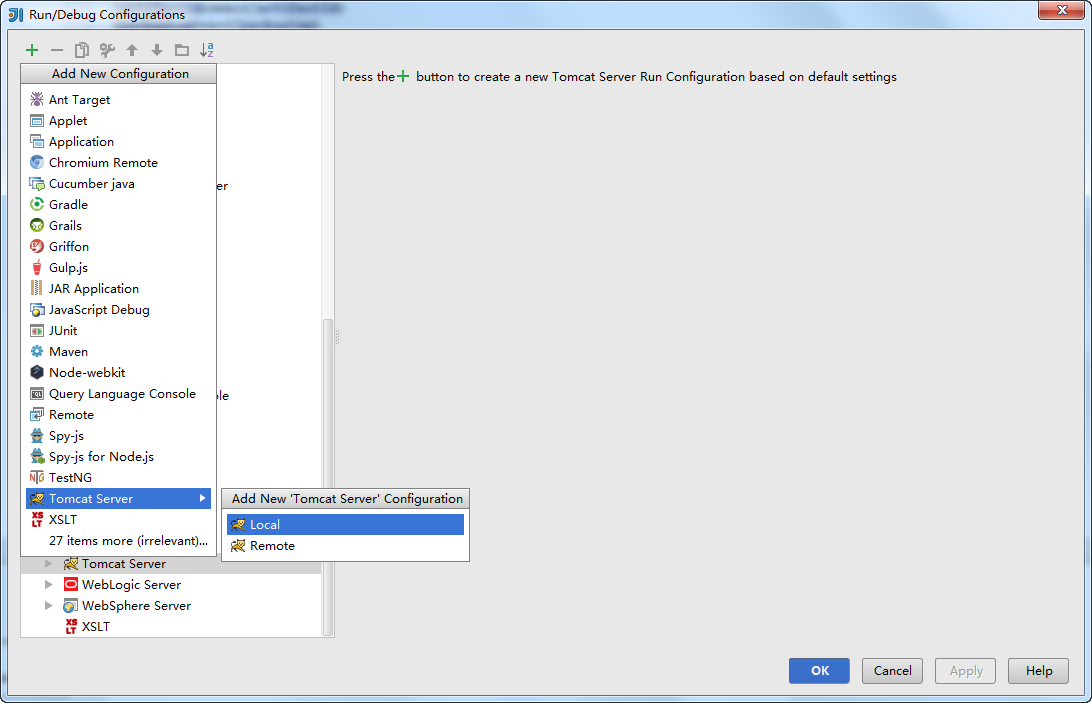
填写Name,选择本地Tomcat
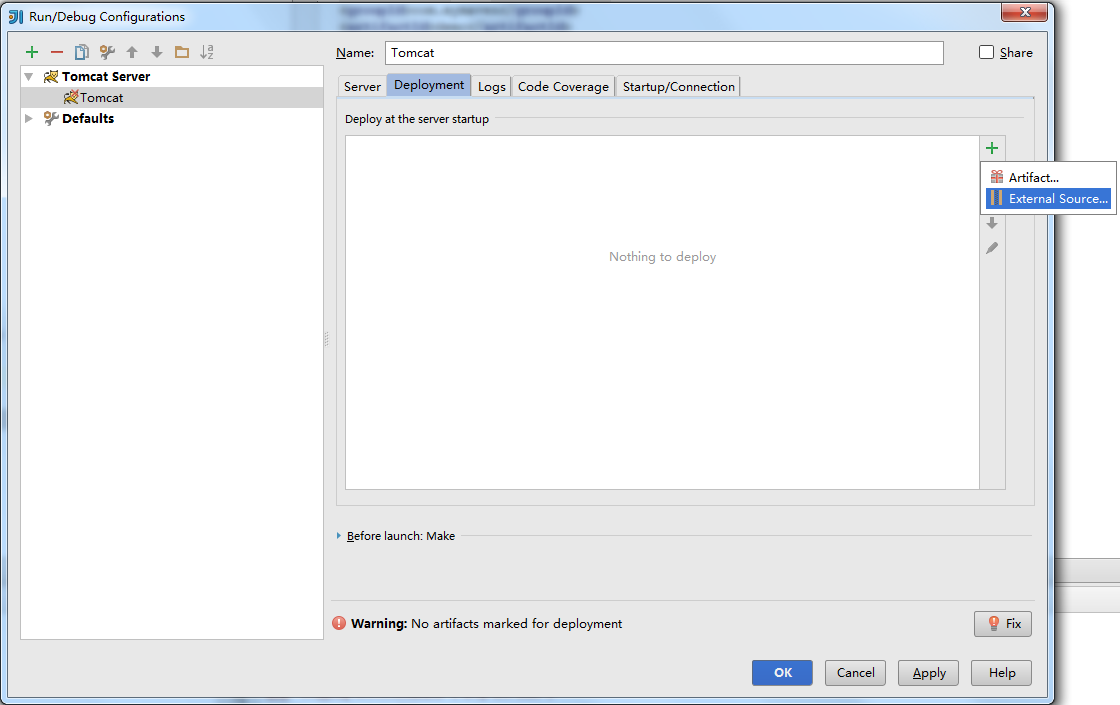
点击”Deployment”面板,然后点击右边的”+”,添加Artifact部署
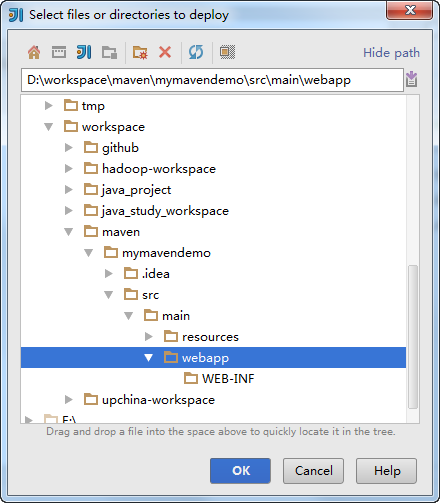
输入路径
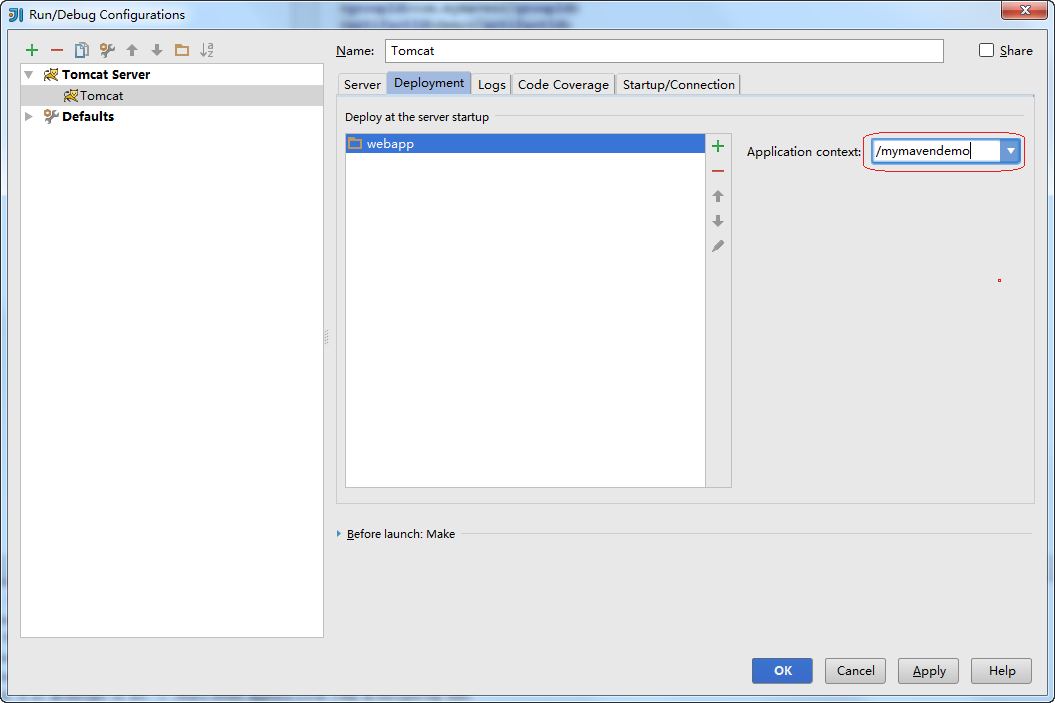
启动tomcat
访问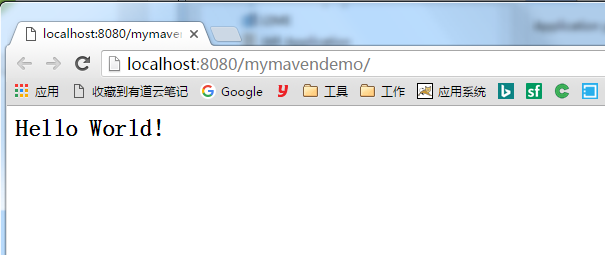
完!
