Heritrix is the Internet Archive’s open-source, extensible, web-scale, archival-quality web crawler project.
一、源码下载
访问GitHub地址:https://github.com/internetarchive/heritrix3
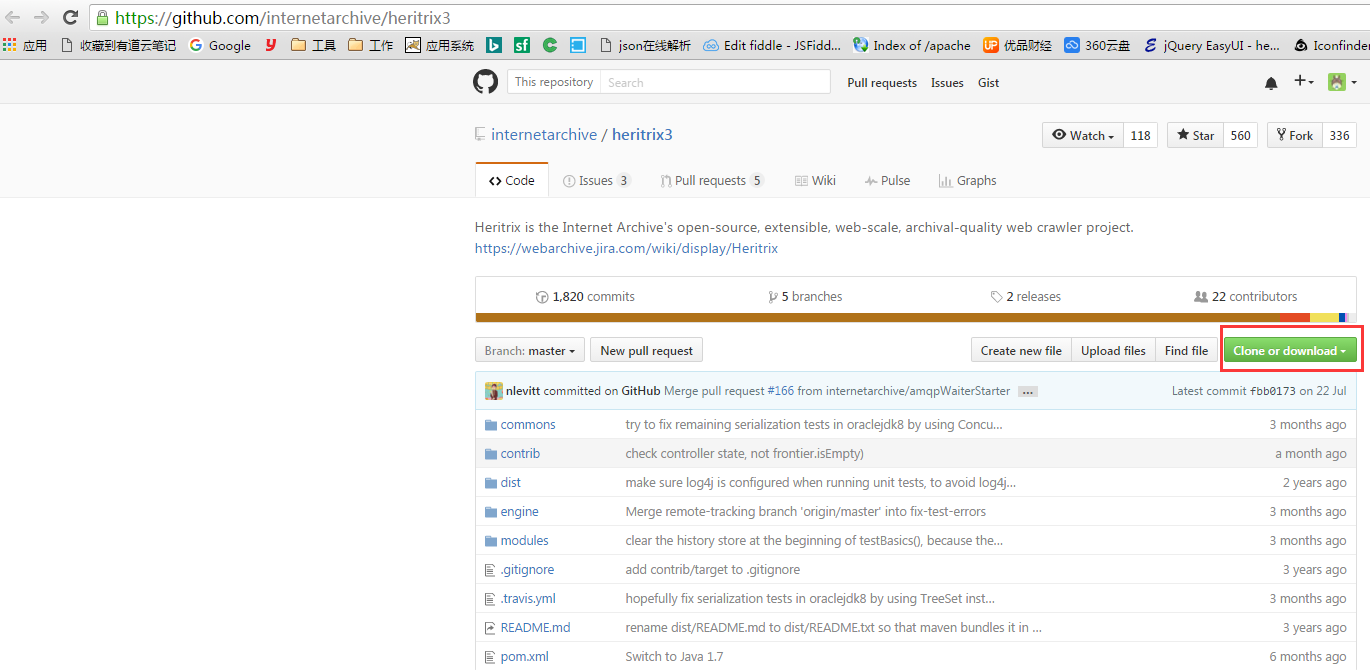
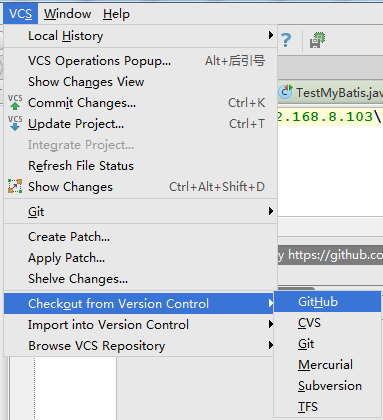
我这里采用Clone的方式,使用的IDE是IntelliJ IDEA
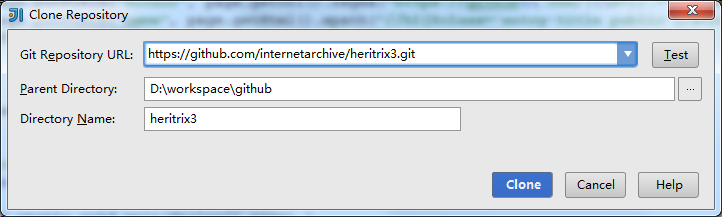
导入完成后的结果如下: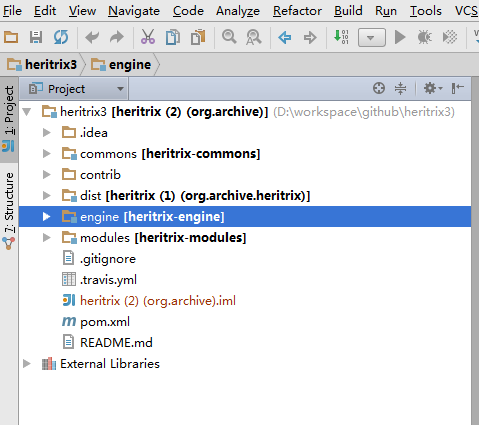
二、启动Heritrix
https://webarchive.jira.com/wiki/display/Heritrix/Running+Heritrix+3.0+and+3.1
尝试启动heritrix,heritrix内核使用jetty所以不需要依附tomcat或者其他web容器。
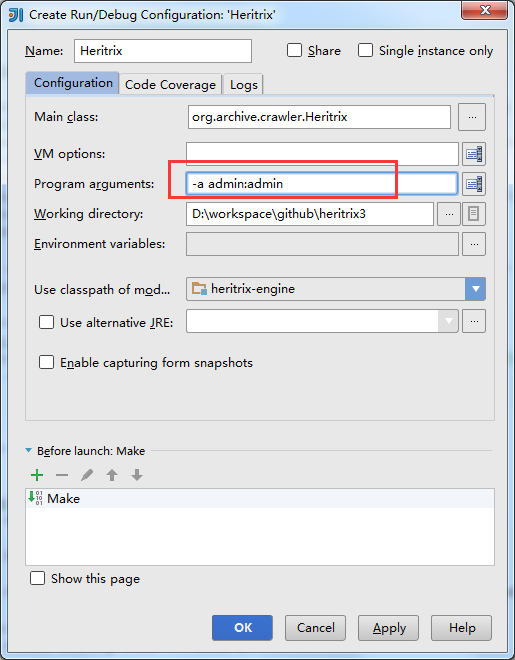
入口类是这个 org.archive.crawler.Heritrix,设置启动参数,如下所示:
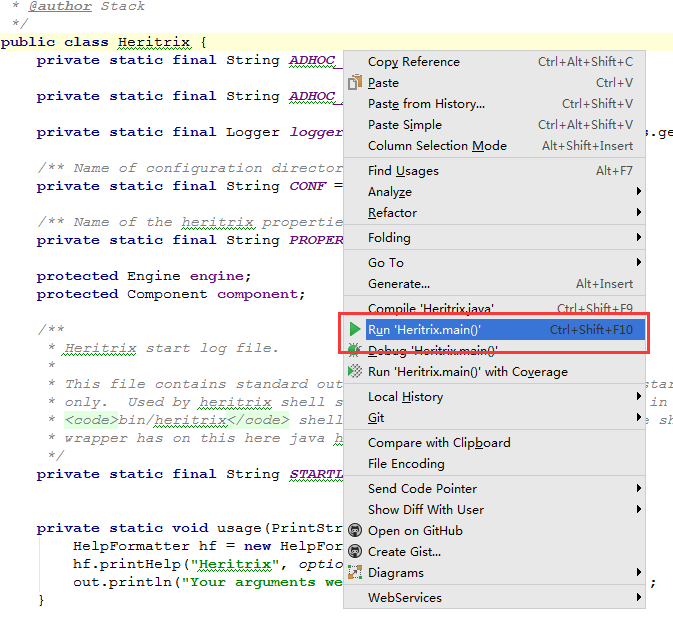
右键 Run ‘Heritrix.main()’启动程序:
启动成功: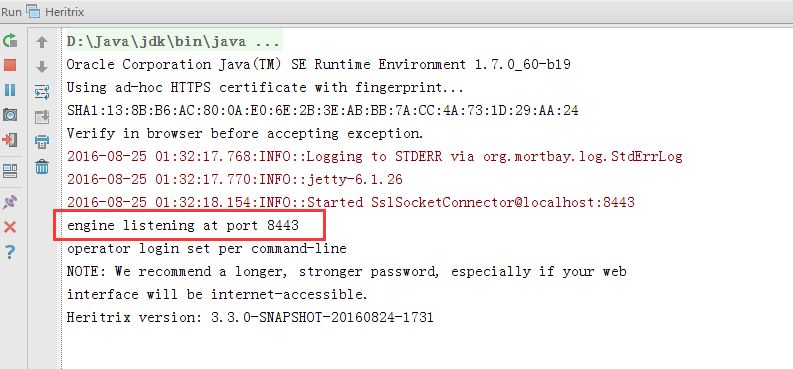
三、基于Web的用户界面
After Heritrix has been launched, the Web-based user interface (WUI) becomes accessible.
The URI to access the Web UI is typically
https://(heritrixhost):8443
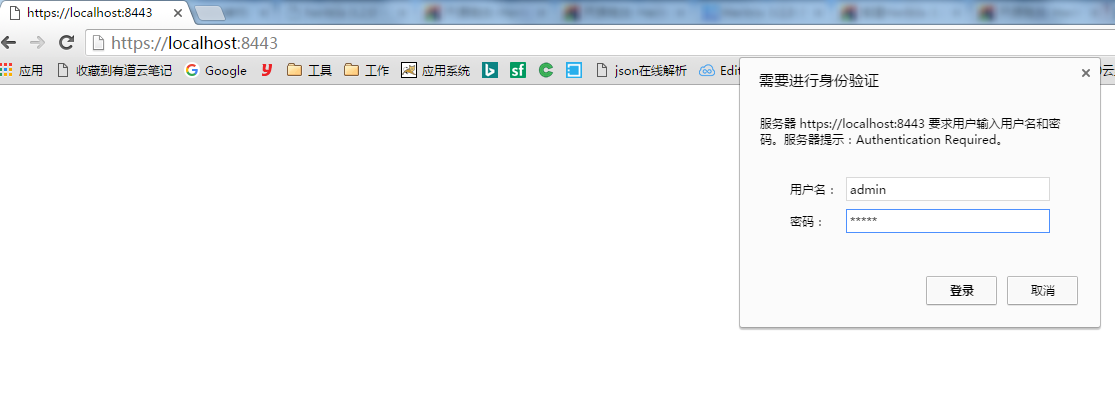
打开浏览器,访问 https://localhost:8443/ ,输入用户名密码,admin,admin。
登录成功后的主控制台页如下所示:
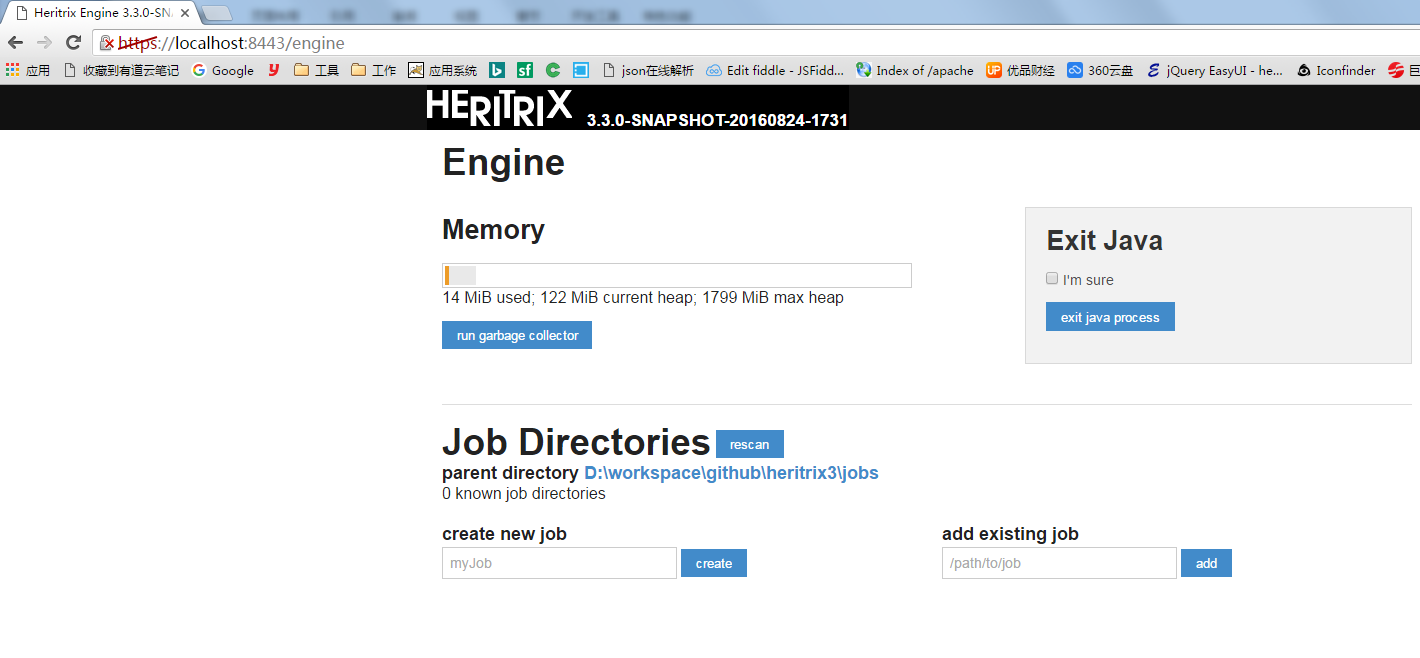
四、运行第一个爬虫任务的快速指南
在主控制台页,新建一个名为’myJob’的Job,创建成功后的界面如下:
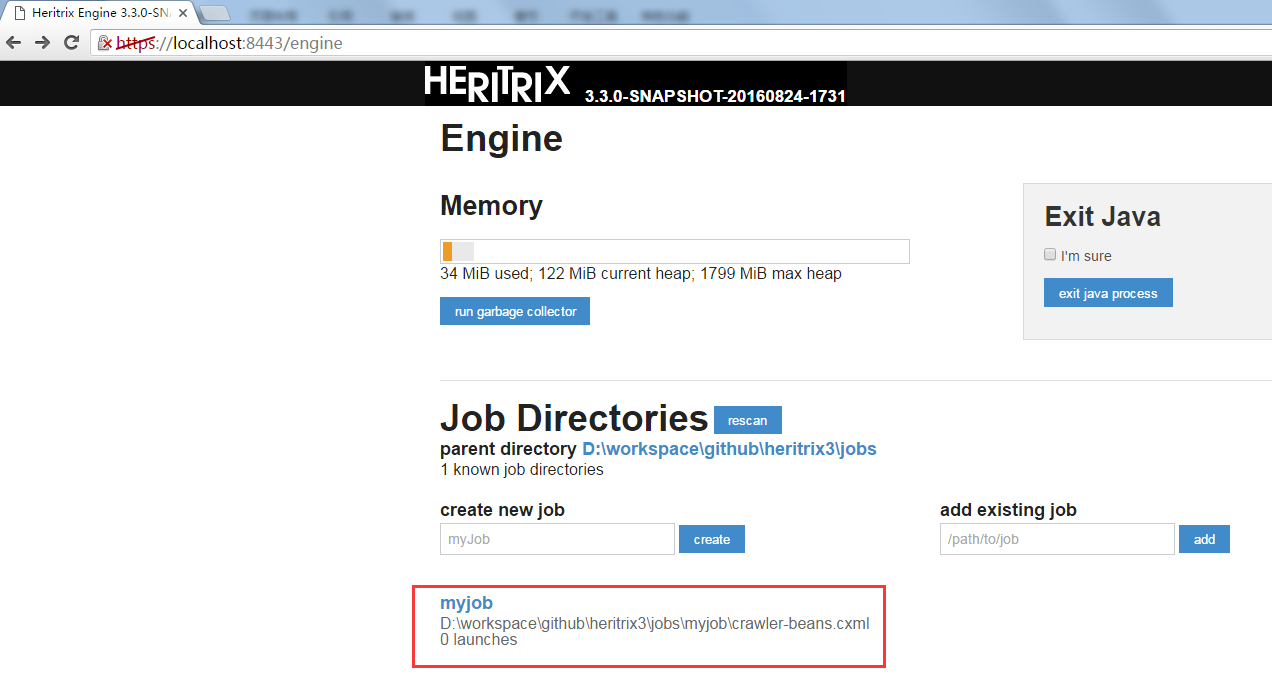
点击新创建的’myJob’的名称链接,进入到’myJob’管理界面,如下所示:
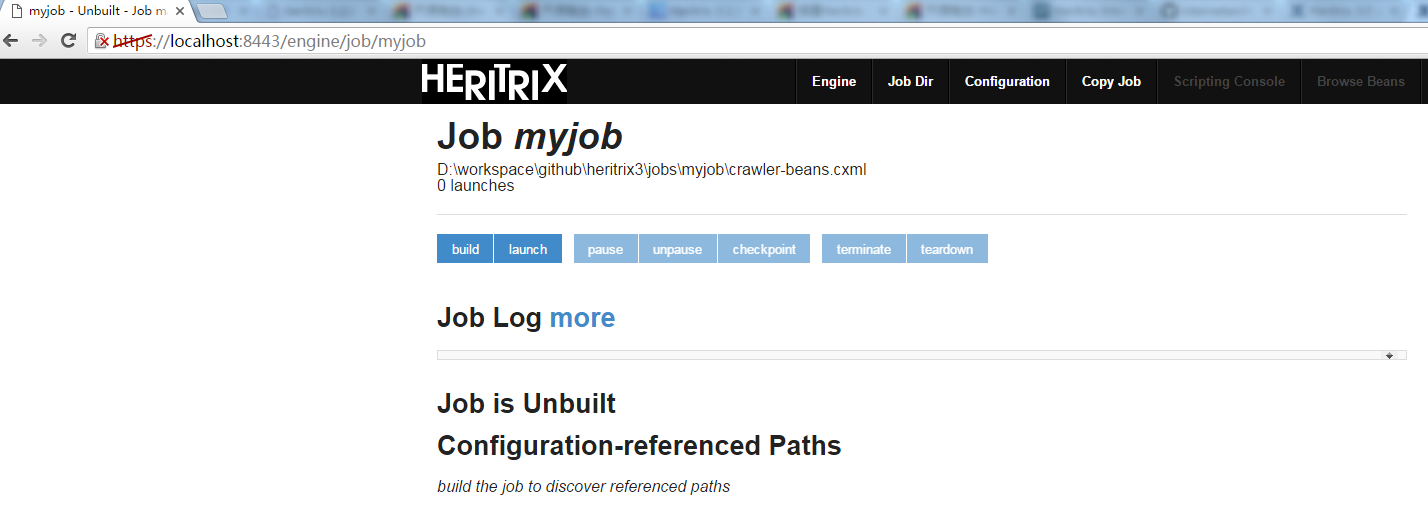
单击工具栏上的”Configuration”链接,进入配置文件的展示/编辑页面如下所示:
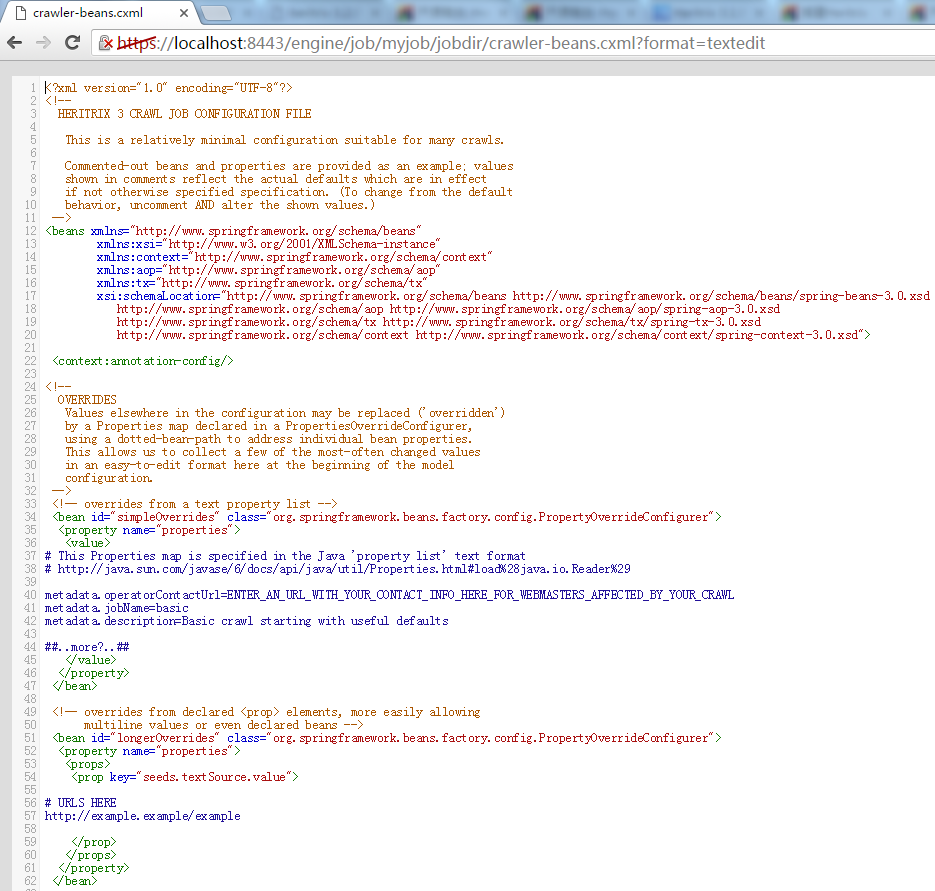
需要进行一些简单的配置,才能使得这个Job正常运行:
A. 将一个有效的值添加到 metadata.operatorContactUrl 属性,如下所示:
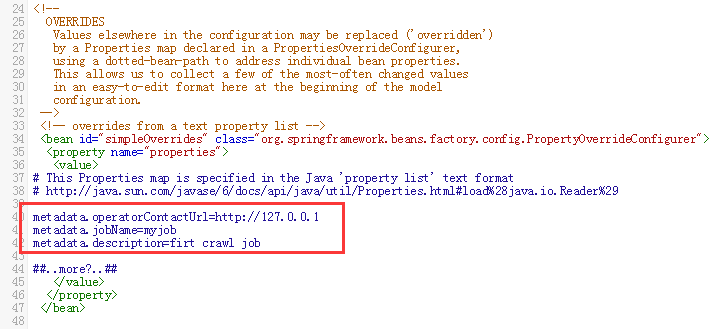
1)metadata.operatorContactUrl 你控制Heritrix的URL,一般是http://127.0.0.1
2)metadata.jobName 表示你的抓取名字,我们刚才创建的是myjob,那就修改为myjob
3)metadata.description 表示对这个抓取任务的简单描述,我们这里就描述为 firt crawl job
B. 接下来,修改爬虫的种子值 longerOverrides 的

C. 完善job信息和本机信息

修改完成后,点击左下角的’save changes’按钮,保存配置。
保存成功后,返回到’myJob’管理界面:
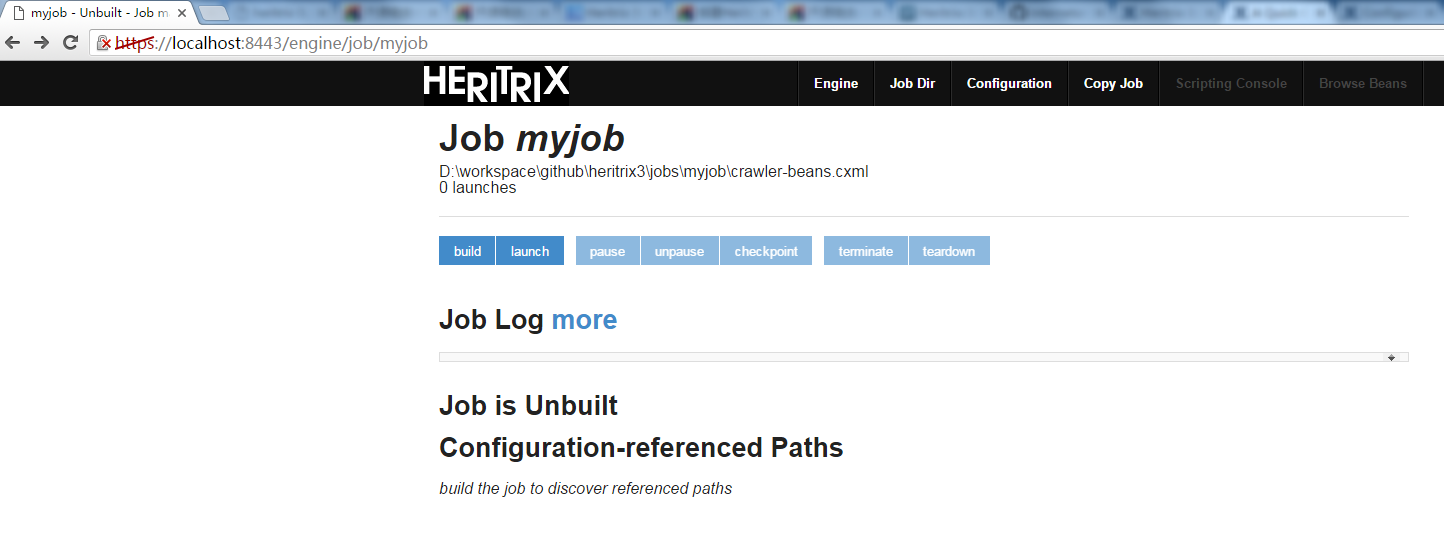
点击’build’按钮,进行build,Job is Ready
点击’Launch’按钮, Job is Active:PREPARING
点击’checkpoint’按钮, Job is Active:PAUSED
点击’unpause’按钮,运行Job,Job is Active:RUNNING
进入文件目录,我们可以看到文件保存的目录
D:\workspace\github\heritrix3\jobs\myjob\20160825031757\warcs 在不断的增大。
如果要看到每个抓取的页面,可以将配置文件的warcWriter这个bean的class改为:
org.archive.modules.writer.MirrorWriterProcessor,这样就下载的网页是以镜像文件的形式保存在,一般存放在项目根目录下的mirror目录下。
五、部署到Linux系统
export JAVA_OPTS=-Xmx1724M
./heritrix -a admin:admin -b 192.168.8.225
六、参考资料
Heritrix3.0教程(三) 开始抓取 http://guoyunsky.iteye.com/blog/1744456
搜索引擎搭建——Heritrix http://blog.wuzx.me/archives/368
Heritrix中的SURT和SurtPrefixedDecideRule .
http://cache.baiducontent.com/c?m=9f65cb4a8c8507ed4fece7631046893b4c4380146d96864968d4e414c4224615023dbfee3a715042889422301cf91e1ab9ab68332a0420b190ca8b4cc9fecf6879877d633047c00149990eafba07628166875b99ed59b0eeab78c4f8c5d2af02049b08532d97f1fb1a474a9d&p=8f769a4780d501f010bd9b7a0757&newp=8b2a971a878511a05ce7822a130a92695803ed603ed4d501298ffe0cc4241a1a1a3aecbf26221006d3c1786501af4e57edf63271340234f1f689df08d2ecce7e70d961&user=baidu&fm=sc&query=Heritrix+SurtPrefixedDecideRule&qid=97273cbc0000dbe4&p1=1
RE: [archive-crawler] Inserting information to MYSQL during crawl
https://groups.yahoo.com/neo/groups/archive-crawler/conversations/topics/508
写入HBase
https://github.com/OpenSourceMasters/hbase-writer
SURT+Rules
https://webarchive.jira.com/wiki/display/ARIH/SURT+Rules
https://webarchive.jira.com/wiki/display/ARIH/Expand+Scope+Rules
Heritrix3.0教程(五) 配置文件crawler-beans.cxml介绍
http://guoyunsky.iteye.com/blog/1744461
Heritrix 3.x API Guide
https://webarchive.jira.com/wiki/display/Heritrix/Heritrix+3.x+API+Guide#Heritrix3.xAPIGuide-LaunchJob