Sharding-JDBC 简介
官网介绍:Sharding-JDBC是一个开源的分布式数据库中间件,它无需额外部署和依赖,完全兼容JDBC和各种ORM框架。Sharding-JDBC作为面向开发的微服务云原生基础类库,完整实现了分库分表、读写分离和分布式主键功能,并初步实现了柔性事务。
本文参考官方Demo采用Spring Boot+MyBatis+MySql+Sharding-JDBC实现分库分表示例。
建库、建表sql
1 |
|
pom文件
1 | <?xml version="1.0" encoding="UTF-8"?> |
分库分表最主要有几个配置:
1.有多少个数据源
2.每张表的逻辑表名和所有物理表名
3.用什么列进行分库以及分库算法
4.用什么列进行分表以及分表算法
分为两个库:demo_ds_0、demo_ds_1
每个库都包含四个表:to_order_0, t_order_1, t_order_item_0, t_order_item_1
使用user_id作为分库列;
使用order_id作为分表列;
配置文件 application.properties
1 | sharding.jdbc.datasource.names=ds_0,ds_1 |
上面配置的分库分表规则如下:
demo_ds_0
├── t_order_0 user_id为偶数 order_id为偶数
├── t_order_1 user_id为偶数 order_id为奇数
├── t_order_item_0 user_id为偶数 order_id为偶数
└── t_order_item_1 user_id为偶数 order_id为奇数
demo_ds_1
├── t_order_0 user_id为奇数 order_id为偶数
├── t_order_1 user_id为奇数 order_id为奇数
├── t_order_item_0 user_id为奇数 order_id为偶数
└── t_order_item_1 user_id为奇数 order_id为奇数
Application
1 |
|
Entity实体类定义
1 | package io.shardingjdbc.example.spring.boot.mybatis.entity; |
1 | package io.shardingjdbc.example.spring.boot.mybatis.entity; |
Mapper层
1 | package io.shardingjdbc.example.spring.boot.mybatis.repository; |
1 | package io.shardingjdbc.example.spring.boot.mybatis.repository; |
1 | <?xml version="1.0" encoding="UTF-8" ?> |
1 | <?xml version="1.0" encoding="UTF-8" ?> |
MyBatis 配置文件
1 | <?xml version="1.0" encoding="UTF-8" ?> |
service 层
1 | package io.shardingjdbc.example.spring.boot.mybatis.service; |
返回生成的order_id和order_item_id
Controller层
1 |
|
使用Postman进行测试
启动服务,使用Postman进行测试:
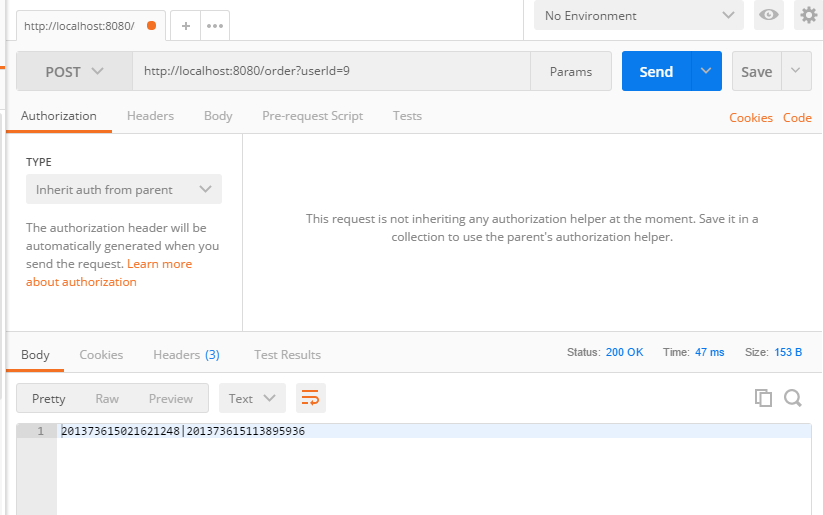
userId从1到9依次插入9条记录,执行结果如下:
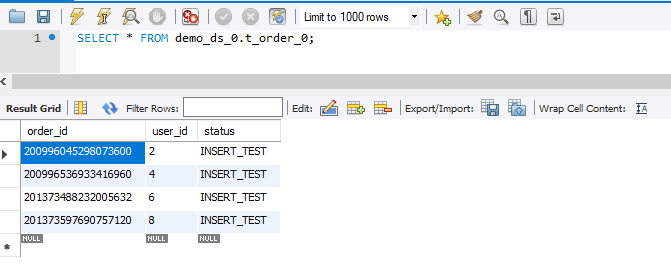
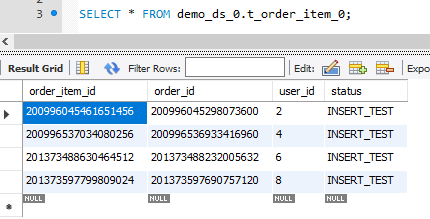
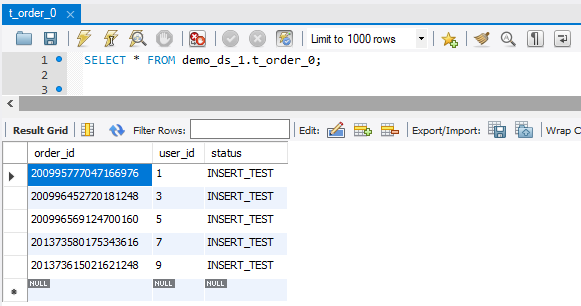
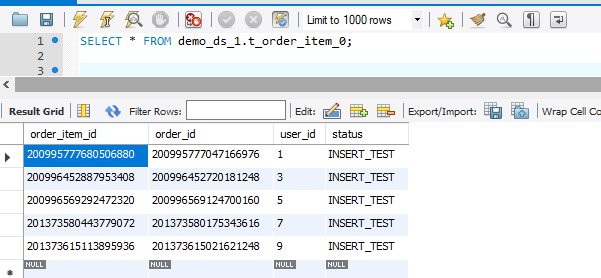
可以看到数据是按照规定的规则写到不同的库和表里了:
demo_ds_0
├── t_order_0 user_id为偶数 order_id为偶数
├── t_order_1 user_id为偶数 order_id为奇数
├── t_order_item_0 user_id为偶数 order_id为偶数
└── t_order_item_1 user_id为偶数 order_id为奇数
demo_ds_1
├── t_order_0 user_id为奇数 order_id为偶数
├── t_order_1 user_id为奇数 order_id为奇数
├── t_order_item_0 user_id为奇数 order_id为偶数
└── t_order_item_1 user_id为奇数 order_id为奇数
这里有个小问题,就是两个库的 t_order_1,t_order_item_1 表中均没有数据,数据分配并不均匀。这是因为Sharding-JDBC采用的默认的分布式自增主键是使用的snowflake算法实现的,说明可以参考sharding-jdbc官网:
http://shardingjdbc.io/docs_cn/01-start/faq/

关于这个问题,考虑修改分表策略为hash分片,或者稍微改造下snowflake 随机初始? 待研究完善…